Robust Regression in R: Use rlm() When Outliers Are Ruining Your lm() Estimates
Robust regression downweights observations with oversized residuals so your fit reflects the bulk of the data, not a few extreme points. In R, MASS::rlm() implements M-estimation via iteratively reweighted least squares, giving coefficients that match lm() on clean data but resist being dragged around when outliers slip in.
Why does one outlier wreck OLS, and what does rlm() do instead?
Ordinary least squares picks the line that minimises the sum of squared residuals. Squaring makes a single distant point contribute hundreds of times more than a typical one, so OLS quietly bends toward outliers even when the rest of the data screams otherwise. rlm() swaps that squared loss for a bounded loss: points far from the fit get less influence, not more. The coefficient table below shows how drastic that swap can be.
The true line is y = 2 + 1.5x. RLM lands almost exactly there. OLS, however, has its intercept inflated to roughly 6.5 and its slope pulled down to 1.35, all because one point out of 30 was extreme. The damage is invisible until you compare the two fits side by side.
The red OLS line tilts upward, chasing the lone outlier at index 10. The blue dashed rlm() line stays glued to the bulk of the points, exactly where the data-generating process placed it. That is the headline benefit, in one picture.
rlm() caps the penalty above a threshold, so a single bad point can no longer dominate the fit.Try it: Push the outlier even further (y[10] <- 130) and refit both models. Predict whether OLS deteriorates further while RLM holds steady, then check.
Click to reveal solution
Explanation: OLS keeps absorbing more of the contamination as the outlier moves further away, because squared loss has no ceiling. rlm() already gave that point a tiny weight, so making it bigger barely matters.
How does M-estimation downweight outliers?
OLS minimises sum(residual^2). M-estimation generalises this to sum(rho(residual)) for some loss function rho() that grows slower than the square. Huber's choice is quadratic near zero (so it behaves like OLS for small residuals) but switches to linear past a cutoff k:
$$\rho_H(r) = \begin{cases} \tfrac{1}{2} r^2, & |r| \le k \\ k\,\bigl(|r| - \tfrac{k}{2}\bigr), & |r| > k \end{cases}$$
Where:
- $r$ = the standardised residual for an observation
- $k$ = the cutoff between "ordinary" and "outlier" residuals; the default for
psi.huberis $k = 1.345$ - $\rho_H(r)$ = the contribution of that observation to the total loss
If you'd rather skip the math, jump to the next code block, the practical takeaway is that residuals beyond k get a linear (not quadratic) penalty.
rlm() doesn't solve this in closed form. It runs iteratively reweighted least squares (IRLS): start with an OLS fit, compute residuals, assign each point a weight that depends on residual size, refit weighted least squares, and repeat until coefficients stop moving.

Figure 1: The IRLS loop. rlm() refits repeatedly, reweighting each point by its residual until coefficients stabilise.
After the loop ends, rlm_fit$w holds the final weight for every observation. Sorting it ascending puts the suspected outliers right at the top.
Point 10, the planted outlier, drops to a weight of 0.022, effectively muted in the final fit. Everything else sits between 0.74 and 1.00, meaning those points contribute roughly as much as they would in plain OLS. The transition is smooth, not a hard cutoff: that is what makes Huber convex and easy to optimise.
Try it: Implement the Huber weight function w(r) = min(1, k/|r|) (the closed-form weight, not the loss rho) and verify that a residual of 3 gets a weight near 0.45.
Click to reveal solution
Explanation: Below k = 1.345, the weight is 1 (full influence, like OLS). Above k, the weight decays as k / |r|, so a residual of 3σ gets weight 1.345/3 ≈ 0.45 and a residual of 10σ gets weight 0.13.
When should you use Huber vs bisquare weights?
psi.huber (the default) is convex: every observation always carries some weight, and IRLS converges to a single global minimum. That is safe but it never fully discards an outlier.
psi.bisquare (Tukey's biweight) is redescending: residuals beyond roughly 4.685σ get weight zero. Severe outliers vanish from the fit entirely. The trade-off is that bisquare is non-convex; IRLS can settle into different local minima depending on its starting point, so a poor initial fit can leave you stuck.
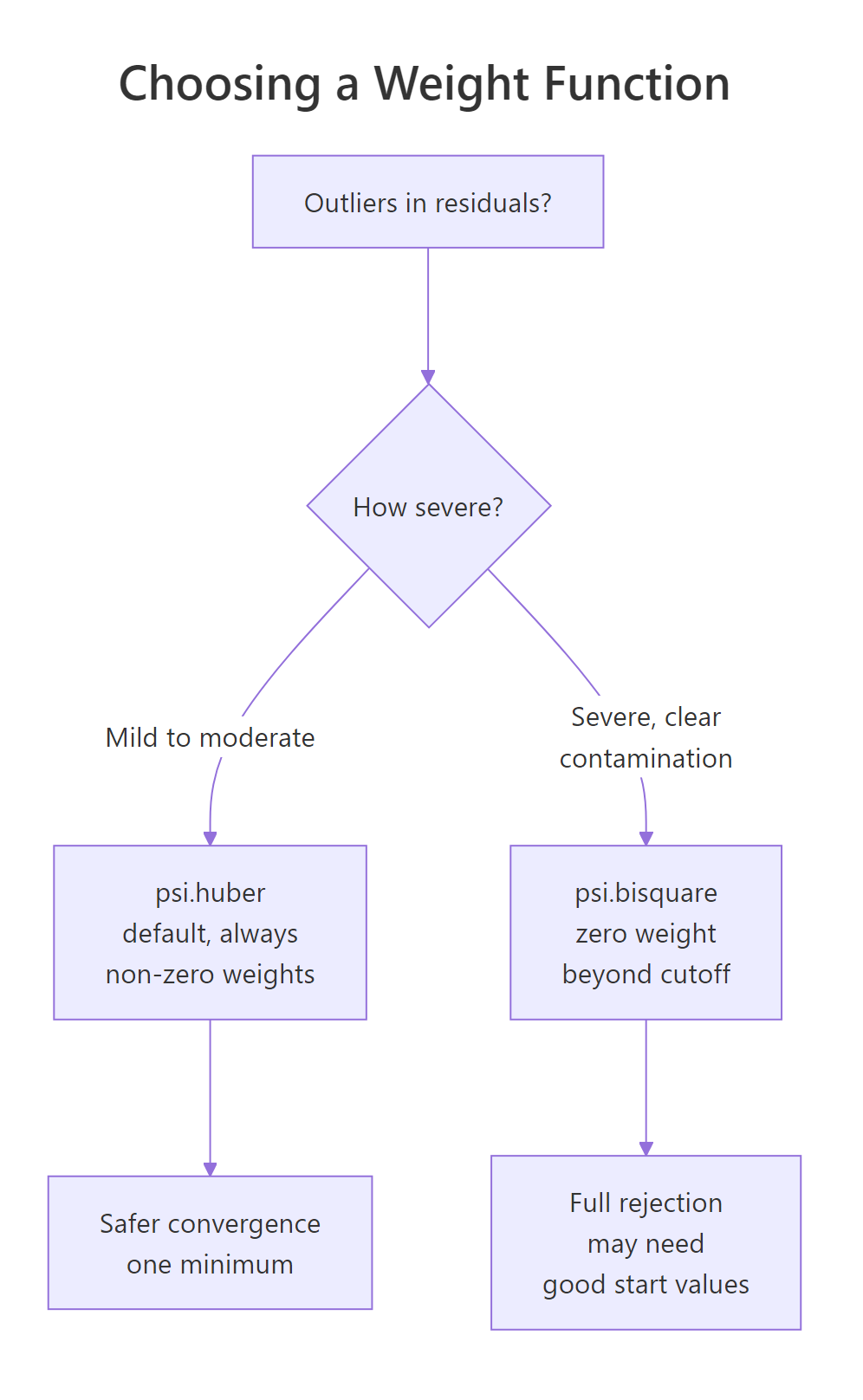
Figure 2: Decision path for picking psi.huber (default) versus psi.bisquare (when severe contamination is present).
The numerical difference is usually small for moderate outliers and noticeable for extreme ones:
Both estimators get within 1% of the truth, but bisquare cuts the residual influence to literally zero past its cutoff. To see why that matters, plot the two weight functions side by side and watch what happens to a residual of 5:
The Huber curve drops gradually but never touches zero. The bisquare curve hits zero at ±4.685σ and stays there. If your data has a few catastrophically wrong rows (data entry errors, sensor faults), bisquare's hard cutoff is exactly what you want. For everyday "long-tailed but real" data, Huber is gentler and harder to break.
rlm() typically draws from a Huber fit. If your bisquare fit and Huber fit agree, you are safe; if they diverge noticeably, investigate before trusting either.Try it: Fit a bisquare model predicting mpg from wt and hp on mtcars. Save it to ex_mtcars_bi and print the coefficients.
Click to reveal solution
Explanation: The coefficients are very close to the OLS fit on mtcars (intercept ≈ 37.2, wt ≈ -3.88, hp ≈ -0.032), confirming mtcars does not have severe outliers. When data is clean, robust regression is a safe drop-in for OLS.
How do you find which points rlm() flagged as influential?
Robust regression does not just give you better coefficients, it also tells you which observations were misbehaving. The recipe is the same every time: pull rlm_fit$w, attach it to the original data alongside residuals and Cook's distance, then sort by weight ascending.
Row 10 lights up on both metrics: it has by far the largest residual, the smallest weight (0.022), and a Cook's distance of 6.4, well past the conventional 4/n threshold of about 0.13. That cross-check is what makes rlm() so valuable for finding outliers, not just resisting them.
rlm_fit$w flags an unusual y value, given the predictors. Cook's distance flags rows whose deletion would change the fit substantially, which can also be triggered by unusual x values (high leverage). They mostly agree, but they answer different questions; use both, especially when your outliers might sit at the edges of the predictor space.Try it: Extract the three rows of diag_df with the smallest weights and store them in ex_bottom3.
Click to reveal solution
Explanation: order(diag_df$weight) returns the row indices of diag_df sorted ascending by weight; head(..., 3) keeps the bottom three.
What are the limits of robust regression?
rlm() shines on y-outliers: rows whose response deviates from the line. It is much weaker on x-outliers, also called high-leverage points, where predictor values sit far from the rest of the data. Because IRLS uses residuals from the current fit, a single high-leverage point can drag the entire line toward itself, keeping its own residual small and its weight close to 1.
Both estimators get the wrong answer (true slope is 1.5, both report about 0.2), and rlm() cheerfully assigns the bad point a weight near 1.0 because the line was pulled to it. This is a known limitation of pure M-estimators. For high-leverage outliers you want MM-estimation via robustbase::lmrob(), which combines a high-breakdown initial estimate with an M-estimator polish, or MASS::rlm(..., method = "MM").
robustbase::lmrob() or MASS::rlm(..., method = "MM"). Run leverage diagnostics first (e.g. hatvalues() or cooks.distance()) so you know which problem you have before reaching for a hammer.Try it: Build a tiny leverage example: ex_lev_x <- c(1:20, 100) paired with ex_lev_y <- c(2 + 1.5 * (1:20) + rnorm(20), 5) (one leverage point with a far-too-low y). Fit rlm() and check whether the slope is close to 1.5.
Click to reveal solution
Explanation: The slope collapses from 1.5 toward 0.3 because the leverage point at x = 100 drags the line down. This is exactly when you would reach for robustbase::lmrob() instead.
Practice Exercises
These capstones combine multiple techniques from the tutorial. Use distinct variable names like my_* so they do not collide with the running notebook state.
Exercise 1: Stackloss benchmark
Fit both OLS and Huber-rlm on the built-in stackloss dataset (predict stack.loss from all three inputs). Print coefficients side by side, then list the five observations with the smallest rlm weights.
Click to reveal solution
Explanation: Rows 1, 3, 4 and 21 are the classic outliers in stackloss, documented by Venables & Ripley. rlm() correctly downweights them, and the Air.Flow and Water.Temp coefficients shift between OLS and rlm. That gap is outlier influence, not noise.
Exercise 2: Contamination sweep
Write a function my_sim(n, p, seed) that simulates n points from y = 2 + 1.5 x + N(0, 0.5), contaminates a fraction p of the y values by adding 30, fits both lm() and rlm(), and returns their slopes. Run it across p = 0, 0.05, 0.10, 0.20 and compare.
Click to reveal solution
Explanation: With clean data (p = 0) the two estimators agree perfectly. As contamination grows, OLS slides linearly toward whatever the outliers want; the rlm slope stays close to 1.5 until contamination is severe (around 20%). That is robustness in numbers.
Complete Example
Here is the workflow you would run on real data: fit OLS, check influence, fit rlm, compare coefficients, list downweighted rows, and refit with bisquare to confirm stability. We use mtcars predicting mpg from hp and wt, a familiar dataset where rlm and lm should mostly agree.
The three estimators agree closely on hp (about -0.03 mpg per unit horsepower) and on wt (about -3.5 to -3.9 mpg per 1000 lb). That tight agreement is the signature of clean data. When the gap between OLS and rlm is small, you can safely report either; when it is large, the gap itself is your diagnostic, telling you outliers are pulling weight somewhere.
Drilling into the rlm weights tells you which rows are pulling:
The Chrysler Imperial is famously heavy yet runs better mpg than its weight predicts; the Toyota Corolla and Fiat 128 are unusually fuel-efficient for their inputs. Robust regression flags these as outliers without removing them, then reports a fit that summarises the typical car in the sample more faithfully than OLS does.
Summary
| Concept | What to remember |
|---|---|
| OLS loss | squared, so outliers dominate the fit |
| rlm loss | bounded rho(), so outliers get downweighted |
psi.huber |
default; convex; always non-zero weight; cutoff k = 1.345 |
psi.bisquare |
redescending; weight = 0 past about 4.685σ; for severe outliers |
| IRLS | iteratively reweighted least squares: fit, weight, refit, repeat |
rlm_fit$w |
per-row weights; small values flag suspect observations |
| Limits | does not fix high-leverage rows or heteroscedasticity; reach for robustbase::lmrob() for MM-estimation |
Figure 3: Robust regression at a glance: problem, method, weights, diagnostics, and limits.
The decision rule is simple. When you suspect your y values may contain a handful of extreme rows, fit rlm() alongside lm(). If they agree, your OLS fit is safe. If they diverge, sort rlm_fit$w ascending and inspect the outliers before reporting any coefficients to anyone.
References
- Venables, W. N. & Ripley, B. D. Modern Applied Statistics with S, 4th edition (Springer, 2002). Chapter 8 covers
rlm()and robust regression in depth. Book site - MASS package,
rlmreference manual (CRAN). Documentation - Huber, P. J. (1964). Robust Estimation of a Location Parameter. Annals of Mathematical Statistics, 35(1), 73-101. JSTOR
- Fox, J. & Weisberg, S. An R Companion to Applied Regression, 3rd edition (SAGE, 2019). Appendix on robust regression. Companion site
- UCLA OARC Stats. Robust Regression R Data Analysis Examples. Tutorial
- Maechler, M. et al.
robustbasepackage (lmrobfor MM-estimation). CRAN page - Wilcox, R. R. Introduction to Robust Estimation and Hypothesis Testing, 5th edition (Academic Press, 2021).
Continue Learning
- Linear Regression Assumptions in R: the assumptions OLS leans on, and how to check them before reaching for robust alternatives.
- Outlier Treatment With R: survey of detection methods (boxplots, Cook's distance, leverage) and remediation strategies before and after fitting.
- Regression Diagnostics in R: the standard diagnostic plot toolkit (residuals, leverage, scale-location) that pairs naturally with
rlm()weight inspection.