Bayesian Statistics in R: Build Genuine Intuition Before Opening Stan or brms
Bayesian statistics in R updates a prior belief about an unknown parameter with observed data, producing a posterior distribution you can plot, integrate, and reason about. Unlike frequentist methods that return a single point estimate plus a confidence interval whose interpretation trips up most students, the Bayesian workflow gives you the full probability curve over plausible parameter values, ready for decision-making.
How does Bayes' theorem turn data into a posterior?
Frequentist tools answer "what is the parameter?" with a point estimate and a confidence interval whose interpretation bends most readers' minds. Bayesian inference flips the question. You start with a prior belief about the parameter, observe data, and end with a posterior distribution: a probability curve over every plausible value. This section shows that update happen in a single line of base R using the Beta-Binomial pair, the simplest example of an analytic posterior.
The math behind every Bayesian update is one line:
$$ p(\theta \mid \text{data}) \;\propto\; p(\text{data} \mid \theta) \cdot p(\theta) $$
Where: $p(\theta)$ is the prior, $p(\text{data} \mid \theta)$ is the likelihood, and $p(\theta \mid \text{data})$ is the posterior. The proportional sign hides a normalizing constant that does not affect the shape of the curve.
Suppose you flip a possibly-biased coin 100 times and see 65 heads. You want to estimate the unknown success probability theta. A Beta(2, 2) prior is mildly skeptical of extreme values, gently centered at 0.5. The posterior comes out in closed form because the Beta family is conjugate to the Binomial likelihood, meaning the posterior stays in the Beta family.
The posterior is Beta(67, 37). Its mean of 0.644 sits between the prior mean of 0.5 and the data proportion of 0.65, gently pulled toward 0.5 by the prior's weight. The 95% credible interval [0.55, 0.73] is the range that contains 95% of the posterior probability mass. That is the interpretation people incorrectly give a frequentist confidence interval.

Figure 1: The Bayesian update workflow. Prior plus data give a posterior, which you then summarize.
Try it: Repeat the calculation with a much tighter prior, Beta(20, 20). What does the posterior mean become and why?
Click to reveal solution
A Beta(20, 20) prior is equivalent to having seen 38 prior flips with 19 heads. Adding the new 100 flips gives a posterior that is pulled noticeably back toward 0.5. A stronger prior carries more weight against the same data, that is the lesson here.
What does a prior actually encode?
A prior is just a probability distribution over the parameter. Anything you can put on a curve, you can use as a prior. The Beta family is convenient for proportions because it lives on [0, 1] and supports two intuitive shape parameters that act like pseudo-counts of prior successes and failures. Three Beta priors illustrate the spectrum from ignorance to strong belief.
Beta(1, 1) is flat: every value of theta is equally plausible before seeing data. Beta(20, 20) is tight around 0.5: a strong belief that the coin is fair. Beta(2, 5) is skewed low: a belief that small values of theta are more likely. Each shape encodes a different domain assumption, and each will pull the posterior in a different direction.
You often have a substantive belief such as "I think theta is between 0.4 and 0.6 with about 90% probability." That language has a direct Beta translation. Search for shape parameters whose 5th and 95th percentiles match the beliefs. A symmetric, moderately tight Beta(45, 45) lands close.
A Beta(45, 45) prior places 90% of its mass between 0.41 and 0.59, a near-perfect match for the stated belief. If you wanted a less tight prior, lower both shape parameters; for a more confident prior, raise them. This is how to translate qualitative belief into a quantitative prior without throwing darts.
Try it: Encode the belief "I think theta is around 0.7 with mild uncertainty" as Beta shape parameters. A good answer keeps most mass in the [0.6, 0.8] range.
Click to reveal solution
Beta(35, 15) has mean 35/50 = 0.7 with 90% of its mass between 0.59 and 0.80. The ratio alpha/(alpha+beta) controls the center; the sum alpha+beta controls how tight the curve is. Combine those two levers to encode any belief on [0,1].
How do prior and likelihood combine into a posterior?
The likelihood is a function of the parameter, given fixed data. It is not itself a probability distribution over theta, just a curve showing which theta values are most consistent with what you saw. Multiply the likelihood curve by the prior curve, normalize so the area is 1, and you have the posterior. Plotting all three on the same axes makes the arithmetic visual.
The likelihood peaks at the maximum likelihood estimate, exactly k/n = 0.65. The prior peaks at 0.5. The posterior peaks slightly below 0.65, pulled toward the prior in proportion to the prior's tightness. With a weak prior and large n, the posterior almost coincides with the likelihood.
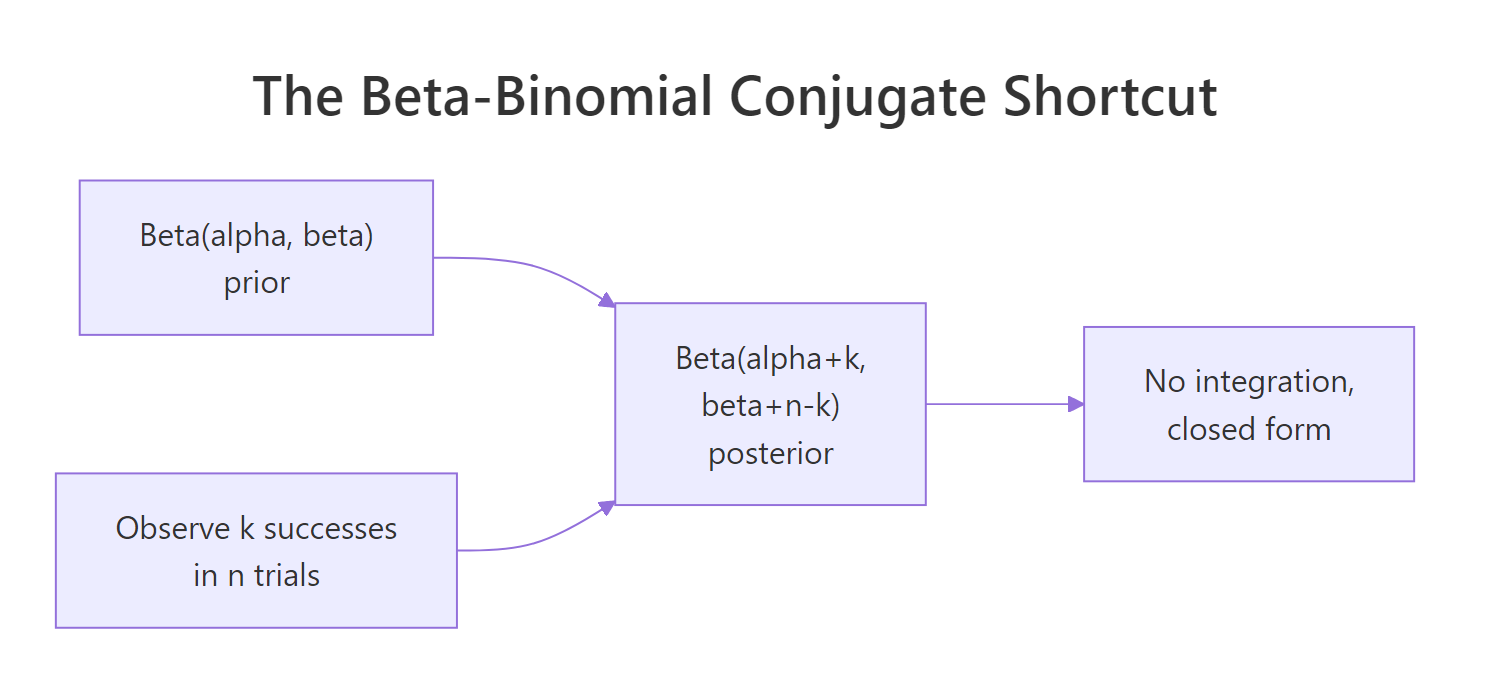
Figure 2: Beta-Binomial conjugate. Closed-form posterior parameters absorb counts of observed successes and failures.
Try it: Suppose you observed 20 heads in 100 flips instead of 65. Recompute the posterior parameters and the posterior mean.
Click to reveal solution
The posterior peaks near 0.21, just above the data proportion 0.20, slightly pulled toward 0.5 by the prior. The shape and the location of the curve both follow the data, while the prior modulates the pull.
How does the posterior shift as more data arrives?
A common worry about Bayesian methods is "what if I pick the wrong prior?" The honest answer: with enough data, the prior gets washed out. Likelihood scales with n, prior does not, so the posterior shifts toward the data as n grows. Showing this with a deliberately bad prior makes the point concrete.
The prior peaks at 0.8 and refuses to budge much for n=10. By n=100 the posterior straddles 0.75. By n=1000 it has converged tightly around the true 0.7. The posterior peak migrates from prior toward truth as the data accumulates.
A subtler property of Bayes' theorem is that updates are order-independent. If you observe one batch, then another, then update sequentially, the result is mathematically identical to combining everything and updating once. The check below verifies that.
Both paths land on Beta(76, 26). Sequential and one-shot updates are mathematically identical, which is why Bayesian methods fit naturally to streaming data: every new observation just nudges the existing posterior into a new posterior of the same family.
Try it: Start from a uniform Beta(1, 1) prior, observe n = 1000 with k = 700 (true theta = 0.7). Where does the posterior peak, and how tight is the 95% credible interval?
Click to reveal solution
A uniform prior plus 1000 observations gives a posterior whose mean is essentially the data proportion, with a 95% credible interval roughly +/- 0.03 around the truth. With this much data, the choice of weak prior barely matters.
How do we summarize a posterior in R?
A posterior is a curve, not a number. To report or act on it you reduce it to a few summaries: a central estimate, an interval that captures most of the mass, and the probability of any event of interest. R provides every Beta family helper you need: dbeta, pbeta, qbeta, rbeta.
The 95% credible interval [0.55, 0.73] is similar in width to the frequentist Wald CI [0.56, 0.74], but the interpretation differs sharply. The Bayesian statement is "given my prior and the data, there is a 95% probability that theta is in this interval." The frequentist statement is the multi-step contortion most students stumble over. The posterior probability of 0.998 that theta exceeds 0.5 is the kind of statement decision-makers can act on directly.
Try it: What is the posterior probability that theta > 0.6?
Click to reveal solution
There is roughly an 82% posterior probability that theta exceeds 0.6 given this prior and these data. Combined with the credible interval, you can quote any tail probability the stakeholder cares about.
What if my prior matters? How do I check sensitivity?
The honest answer to "what if my prior is wrong?" is to try several reasonable priors and see whether the conclusion changes. If three plausible priors give similar posteriors, you have a robust answer. If they give materially different posteriors, that is itself a finding to report alongside the analysis. The check is cheap with conjugate priors.
All three priors produce posterior means within 0.04 of each other and 95% credible intervals that overlap heavily. The posterior probability that theta > 0.5 ranges from 0.992 to 0.999, well above any reasonable decision threshold. The conclusion that theta likely exceeds 0.5 is robust to a reasonable change of prior. That is exactly what you want to be able to report.
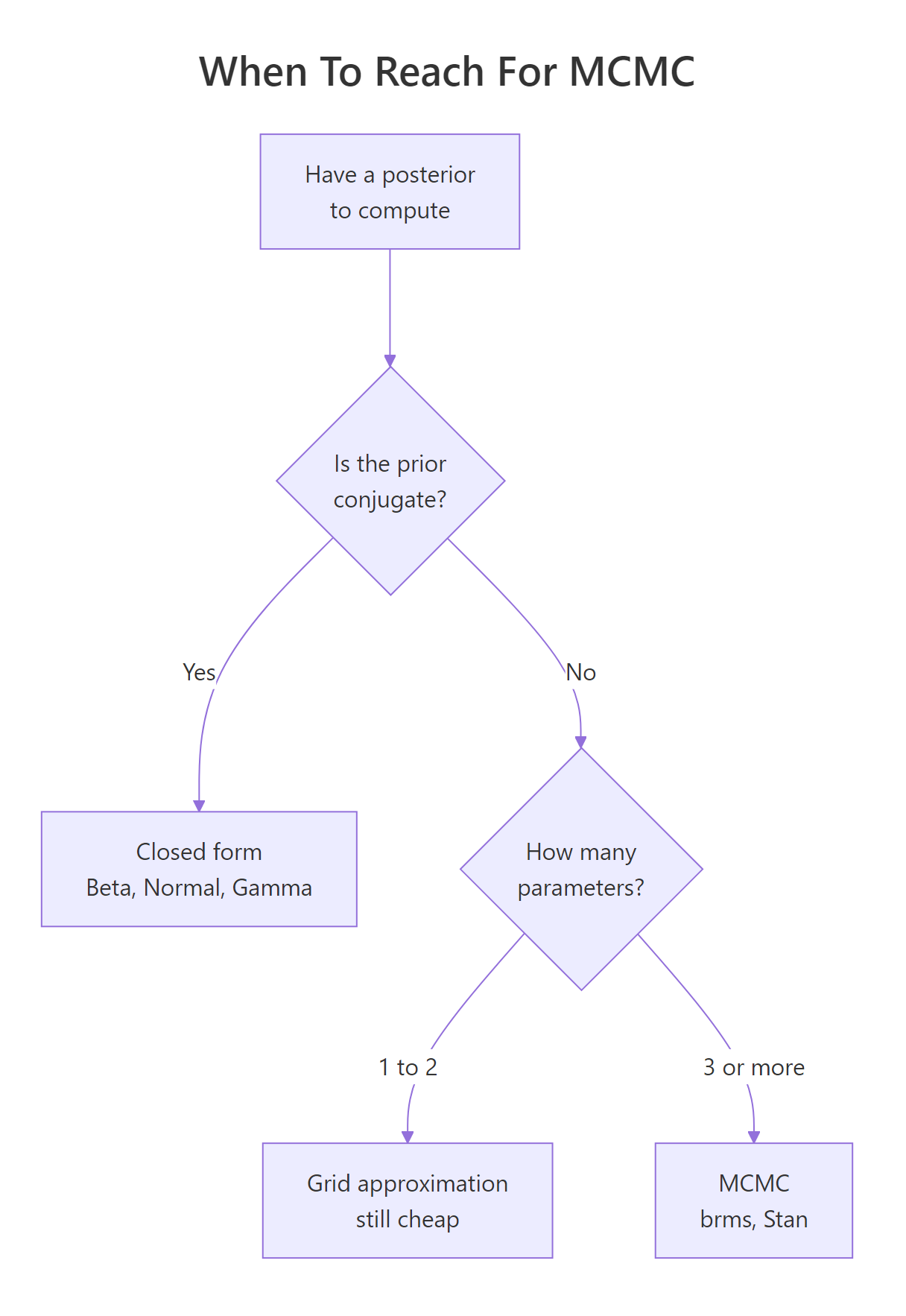
Figure 3: When to reach for MCMC. The decision tree from conjugate to grid to sampling.
Try it: With a smaller dataset (n = 20, k = 15), check sensitivity under three prior strengths: Beta(2, 2), Beta(50, 50), Beta(200, 200). How much do posterior means differ?
Click to reveal solution
With only 20 observations, the prior carries real weight. The weak Beta(2, 2) prior lets the data dominate (posterior mean 0.71 against data 0.75). The strong Beta(200, 200) prior pulls hard toward 0.5 (posterior mean 0.56). With small samples, prior choice is consequential and you must report sensitivity.
When do we need MCMC instead of analytic posteriors?
The Beta-Binomial pair is conjugate, meaning the posterior stays in the same Beta family as the prior. Conjugate priors exist for several common likelihoods (Normal-Normal, Gamma-Poisson) and they all give closed-form posteriors. Once you leave that small family, or once you have more than a couple of unknown parameters, the integral that normalizes the posterior becomes intractable. Grid approximation on a 2-parameter Normal model shows the limit of brute force.
For two unknowns we computed 80 x 80 = 6,400 posterior values, which fits in memory. Add a third parameter and you need 80^3 = 512,000 cells. Add a fourth and you are in the millions. This combinatorial blow-up is why MCMC exists: it samples from the posterior without ever computing it on a grid.
Try it: Roughly how many cells does grid approximation need for 5 parameters at 50 points each?
Click to reveal solution
Over 312 million cells. The cost grows exponentially in the dimension. By six or seven parameters even cluster-scale grids are infeasible, and that is exactly the wall MCMC was invented to scale past.
Practice Exercises
Exercise 1: Twitter survey
A Twitter survey asks 50 users whether they like a new feature; 32 say yes. Use a Beta(2, 2) prior to compute the posterior, the posterior mean, and a 95% credible interval over the true approval rate.
Click to reveal solution
Posterior is Beta(34, 20), mean 0.63, 95% CrI [0.49, 0.75]. The credible interval includes 0.5, so you cannot yet rule out the possibility that the feature is no better than a coin flip.
Exercise 2: Sequential update equals one-shot update
Observe two batches of 50 flips: 35 heads in the first, 40 heads in the second. Show that updating once after each batch gives the same posterior as combining everything and updating once with n = 100, k = 75. Use a Beta(1, 1) prior.
Click to reveal solution
Both paths land on Beta(76, 26). Bayes' theorem is order-independent and incremental.
Exercise 3: Three-prior sensitivity
You observe 20 successes in 30 trials. Compute posteriors and posterior P(theta > 0.5) under three priors: Beta(1, 1), Beta(2, 5), Beta(8, 2). Report all three posterior means and tail probabilities. Are the conclusions robust?
Click to reveal solution
All three priors agree directionally that theta probably exceeds 0.5 (tail probability between 0.85 and 0.99). The skeptical prior cools the conclusion by about 0.1, the optimistic prior warms it. With only 30 observations the prior matters, but the directional conclusion survives all three reasonable priors.
Complete Example: Customer Satisfaction Survey
A SaaS company surveys 200 customers and finds 132 say they would recommend the product. Marketing wants to claim the recommendation rate is "above 60%." Quantify that claim under three priors: a skeptical Beta(2, 5), an uninformative Beta(1, 1), and an optimistic Beta(8, 2). Report posterior summaries and the posterior probability that theta > 0.6 under each.
All three priors give posterior probability above 90% that the true recommendation rate exceeds 60%. The skeptical prior is the most conservative (90.9%), and even it strongly supports marketing's claim. The conclusion is robust to a reasonable change of prior, which is exactly the kind of report a careful Bayesian analyst delivers: a primary estimate plus an explicit sensitivity check.
Summary
| Question | Frequentist answer | Bayesian answer |
|---|---|---|
| Best estimate of theta | k/n point estimate | Posterior mean (Beta(alpha+k, beta+n-k) for proportions) |
| Uncertainty | 95% confidence interval | 95% credible interval |
| Interpretation of interval | "If we repeated the experiment, 95% of such intervals would cover theta." | "Given prior and data, there is a 95% probability that theta is in this interval." |
| Probability of an event | Not well-defined (theta is fixed, not random) | Computed by integrating the posterior |
| What you input | Data only | Prior plus data |
| What you output | Single number plus CI | Full probability distribution |
| Robustness check | Power, replication | Prior sensitivity analysis |
References
- McElreath, R. Statistical Rethinking, 2nd ed. Chapman & Hall, 2020. Chapters 1-2 build the prior-likelihood-posterior intuition with worked simulations.
- Gelman, A., Carlin, J. B., Stern, H. S. et al. Bayesian Data Analysis, 3rd ed. Chapman & Hall, 2013. Chapters 1-2 cover the foundations.
- Johnson, A. A., Ott, M. Q., Dogucu, M. Bayes Rules! An Introduction to Applied Bayesian Modeling. Chapman & Hall, 2022. Open access at bayesrulesbook.com. Chapter 3 is the canonical Beta-Binomial reference.
- CRAN Task View: Bayesian Inference. cran.r-project.org/web/views/Bayesian.html. Curated list of R packages for Bayesian analysis.
- Coghlan, A. A Little Book of R for Bayesian Statistics. a-little-book-of-r-for-bayesian-statistics.readthedocs.io. Practical proportion-estimation worked examples.
- Gelman, A. and the Stan team. "Prior choice recommendations." github.com/stan-dev/stan/wiki/Prior-Choice-Recommendations. The community standard for principled prior choice.
- R-bloggers. "An Intuitive Look at Binomial Probability in a Bayesian Context." r-bloggers.com, 2020. Gold-merchant analogy and grid approximation animation.
Continue Learning
- Bayes' Theorem in R, the discrete foundation, worked through medical-test reasoning.
- Gamma & Beta Distributions in R, full mechanics of the Beta family used as priors here.
- Maximum Likelihood Estimation in R, the frequentist counterpart to compare against the Bayesian workflow.