Ordinal Logistic Regression in R: MASS::polr() & Proportional Odds
Ordinal logistic regression models an ordered outcome, like grades (D < C < B < A) or satisfaction ratings, using a single set of slope coefficients and one intercept per cut-point. In R, the standard tool is MASS::polr(), which fits a cumulative-logit model under the proportional odds assumption.
How do you fit an ordinal logistic regression in R?
The workflow has three pieces: make the outcome an ordered factor, call polr() with a formula, and read the coefficient table. Let's simulate 500 students with study hours, attendance, and prior GPA, then predict their final grade. Because grades have a natural order, ordinal regression respects that order instead of treating the outcome as four unrelated classes.
All three slope coefficients are positive, which means more study hours, higher attendance, and higher prior GPA each push students toward the higher grade categories. The three intercepts D|C, C|B, B|A are the cut-points that separate adjacent grades on the log-odds scale. Their widening spacing (2.85, 4.98, 7.82) tells us the "A" category is reached only when the combined predictors push the linear score well past the other cuts.
Hess = TRUE saves the Hessian matrix at the optimum. Without it, summary() cannot compute standard errors or t-values, so always include it unless you have a reason not to.Try it: Fit a polr() model using only study_hours as the predictor. Does its slope match the one from the full model?
Click to reveal solution
Explanation: The single-predictor slope is larger (~0.39 vs. 0.29) because it absorbs effects that the full model attributes to attendance and prev_gpa. Omitting predictors correlated with study_hours inflates its apparent effect.
When should you use ordinal logistic regression?
Choose your model from the outcome variable, not from habit. Ordinal logistic regression sits between plain binary logistic regression and multinomial logit, and it is the right choice whenever the categories have a natural order that a multinomial model would throw away.
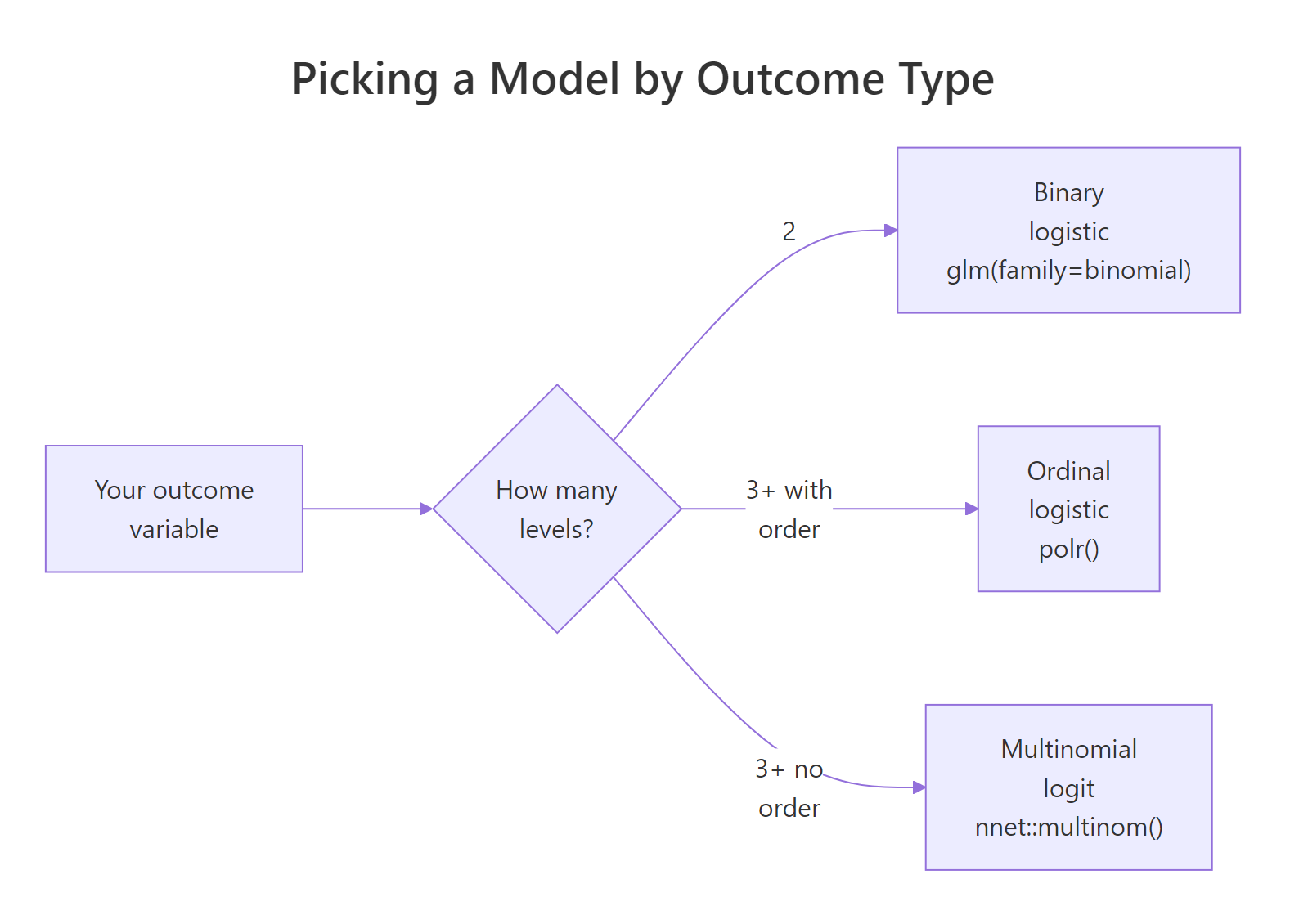
Figure 1: Decision flow for picking a model from the type of outcome variable.
A tempting alternative is to cast the grades as numbers (D=1, C=2, B=3, A=4) and use linear regression. That works mechanically, but it hides two strong assumptions: that the distance from D to C equals the distance from B to A, and that a predicted 2.7 makes sense as a grade.
The linear model produces fractional predictions like 2.73 that do not map to any grade, and its coefficients implicitly assume equal spacing between grades. polr() avoids both traps by modelling the ordering without forcing a specific spacing.
Try it: Convert the character vector c("Low","High","Medium","Low","High") into an ordered factor with levels Low < Medium < High.
Click to reveal solution
Explanation: The levels argument names the allowed values in order, and ordered = TRUE tells R that the order is meaningful, not alphabetical.
What does the proportional odds assumption mean?
Ordinal logistic regression imagines a single continuous "ability" score behind your categorical outcome, and then carves that score into ordered bins with cut-points. The same slope describes how predictors move that underlying score, regardless of which bin boundary you look at.
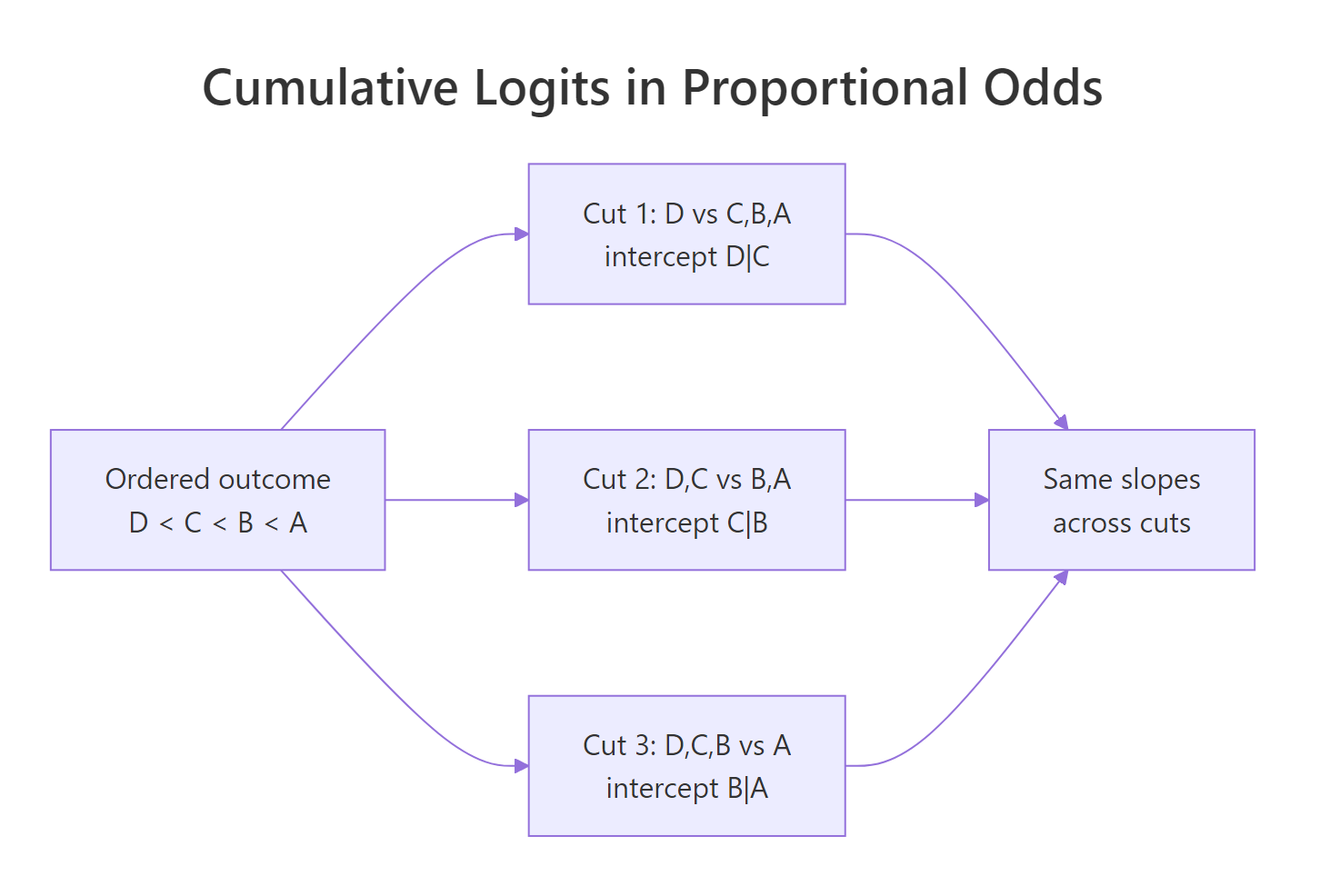
Figure 2: Cumulative cut-points share one slope set under the proportional odds assumption.
Formally, for an outcome with $J$ ordered levels and cut-points $j = 1, \dots, J-1$, the cumulative-logit model is:
$$\text{logit}\bigl(P(Y \le j \mid x)\bigr) = \alpha_j - (\eta_1 x_1 + \eta_2 x_2 + \dots + \eta_p x_p)$$
Where:
- $P(Y \le j \mid x)$ = probability that the outcome is at or below category $j$
- $\alpha_j$ = the $j$-th intercept (cut-point), one per non-top category
- $\eta_k$ = slope for predictor $x_k$, shared across all cut-points
- The minus sign is R's convention in
polr(): positive $\eta$ means larger $x$ raises the probability of higher categories
Let's confirm that the model's intercepts and slopes actually produce the cumulative probabilities we expect.
The first row is the cumulative "at or below" probabilities straight from the formula; the second row is the per-category probabilities, which are the differences between adjacent cumulative values plus the endpoints. Both agree: this student is most likely to land in category B.
Try it: Using the fitted model, compute the cumulative probability P(grade <= C) for a student with 8 study hours, 75% attendance, and 3.0 GPA.
Click to reveal solution
Explanation: predict(type = "probs") gives the four per-category probabilities; summing the "D" and "C" entries recovers the cumulative probability P(grade <= C) ≈ 0.70 for this student.
How do you interpret polr() coefficients and odds ratios?
The raw coefficients from summary(model) live on the log-odds scale, which is awkward to talk about. Exponentiating each coefficient converts it into an odds ratio: how many times the odds of being in a higher category multiply for a one-unit increase in the predictor.
Each extra study hour multiplies the odds of a higher grade by about 1.33 (a 33% increase), holding attendance and prior GPA fixed. A 1-point jump in prior GPA multiplies those same odds by 3.72, so prior GPA is the strongest driver among the three. The 95% CIs are all well above 1, confirming each effect is statistically meaningful.
polr() uses a minus sign on the slopes. The parameterization is logit P(Y ≤ j) = αⱼ − η·x, which flips the usual sign intuition for a second. If summary() shows a positive η, larger x makes higher categories more likely, which is what you want. Always read the sign from the output, not from memory.Try it: Compute the odds ratio for a 5-unit increase in study_hours. Hint: the OR for a k-unit change is exp(k * beta).
Click to reveal solution
Explanation: Multiplying the slope by 5 and exponentiating gives the odds ratio for a 5-unit change. Five extra study hours roughly quadruple the odds of being in a higher grade category.
How do you check the proportional odds assumption?
The proportional odds assumption says the slopes are the same at every cut-point. The cleanest way to check it is to fit one binary logistic regression at each cut-point and compare the slopes side by side. If the slopes stay close to each other, the assumption is reasonable; if they swing wildly, it is not.
The three rows of slopes for study_hours, attendance, and prev_gpa sit within a narrow band of each other (for example, 0.29 / 0.28 / 0.28 for study hours). That close agreement is exactly what proportional odds predicts, so for this simulated data the assumption clearly holds.
brant::brant(model) runs the formal Brant test of parallel slopes, and car::poTest(model) offers an equivalent test from John Fox. Both operate on a fitted polr() object and return per-predictor p-values. The logic is identical to the manual comparison above; p-values flag the predictors whose slopes vary across cut-points.When the assumption fails, you have three pragmatic options:
- Partial proportional odds with
VGAM::vglm(..., family = cumulative(parallel = FALSE ~ x)), which lets only the offending predictor vary its slope across cuts. - Multinomial logit with
nnet::multinom(), which drops the ordering entirely and estimates a separate set of slopes per category. - Collapse categories by combining adjacent levels if the data does not support distinguishing them.
Option 1 is usually the cleanest compromise because it keeps the ordering for the predictors that behave proportionally and only relaxes the rule where needed.
Try it: Fit a single binary logistic regression for "grade >= B" and compare its study_hours coefficient to the polr() slope (0.286).
Click to reveal solution
Explanation: The binary logit estimate (0.281) sits right on top of the polr() slope (0.286). That agreement is the proportional odds assumption working as advertised.
How do you make predictions with polr()?
polr() offers two prediction types. predict(type = "class") returns the single most likely category per row, while predict(type = "probs") returns the full probability matrix with one column per level. Both come from the same fitted cut-points and slopes.
Every row of preds_prob sums to 1, and the class returned by type = "class" is always the column with the largest probability. This gives you two useful outputs at once: a hard label for deployment and a soft probability for downstream risk decisions.
Probability curves show how each grade's chance shifts as a predictor moves, keeping everything else fixed. A long tradition in regression teaching says: when in doubt, plot.
Reading left to right, the "D" and "C" curves fall while the "B" and "A" curves rise. Every vertical slice of the plot sums to 1 because the four grades exhaust the outcome space. The curves never cross except at the cut-points, a direct visual confirmation of proportional odds.
table(). table(predicted = predict(model), observed = student$grade) gives you a quick snapshot of where the model gets it right and where it confuses adjacent categories (which is usually the hardest place to pull signal from in an ordinal problem).Try it: Predict the grade probabilities for a single new student with 8 study hours, 70% attendance, and 2.8 GPA.
Click to reveal solution
Explanation: Most of this student's probability mass is on C (0.41), with D close behind (0.26). The model is telling us a low-effort, low-attendance student with a sub-3.0 prior GPA is most likely to finish in the bottom two categories.
Practice Exercises
These bring together the concepts from the full tutorial. Each one is solvable with only the functions and ideas we have already used.
Exercise 1: Test whether an interaction improves fit
Fit a second polr() model that adds the interaction study_hours:prev_gpa to the full model, and use anova() to test whether the interaction is worth keeping.
Click to reveal solution
Explanation: The likelihood ratio p-value (~0.49) is well above 0.05, so the interaction does not improve fit. Stick with the simpler cap_fit1. This is how you justify dropping a fancy-looking predictor.
Exercise 2: Build a reusable odds-ratio function
Write grade_odds_ratio(fit, predictor, delta) that returns the odds ratio for a delta-unit change in any named predictor. Test it on a 0.5-unit increase in prev_gpa.
Click to reveal solution
Explanation: A 0.5-point jump in prior GPA multiplies the odds of a higher grade by ~1.93. Wrapping the calculation in a function lets you sweep the same logic across predictors or delta sizes without copy-pasting.
Exercise 3: Check proportional odds for a single predictor
Focus the proportional odds check on prev_gpa alone. Fit three binary logistic regressions at the three cut-points and compare only the prev_gpa coefficient across them. Decide whether you would trust the assumption for this predictor.
Click to reveal solution
Explanation: The three prev_gpa slopes (1.40, 1.29, 1.27) fall inside a narrow band. That agreement means the proportional odds assumption is credible for this predictor and you don't need a partial proportional odds model.
Complete Example
Here is an end-to-end workflow on the simulated student data: split 80/20 train/test, fit polr(), compute odds ratios, predict on the test set, and score the result with a confusion matrix.
The off-diagonal errors cluster next to the diagonal: the model mixes up adjacent grades far more than it mixes up D with A. That is the hallmark of a well-specified ordinal model: when it errs, it errs one step at a time.
Summary
| Concept | Function / Check | What it gives you |
|---|---|---|
| Fit the model | MASS::polr(y ~ x, data, Hess = TRUE) |
Slopes + cut-point intercepts |
| Read the output | summary(model) |
Coefficient table with t-values |
| Odds ratios | exp(cbind(coef(model), confint(model))) |
OR + 95% profile CIs |
| PO assumption check | Binary logits at each cut, or brant::brant() / car::poTest() |
Evidence slopes are parallel |
| If PO fails | VGAM::vglm() (partial PO), nnet::multinom() (no order) |
Relaxed models |
| Predict | predict(model, type = "class") and type = "probs" |
Labels and full probability matrix |
| Visualise | Probability curves across one predictor, with ggplot2 |
How predictions shift per x |
References
- Venables, W. N. and Ripley, B. D., Modern Applied Statistics with S, 4th ed., Springer (2002). Origin of the
MASSpackage andpolr(). Link - MASS package
polrreference manual. Link - UCLA OARC, Ordinal Logistic Regression: R Data Analysis Examples. Link
- Brant, R. (1990). Assessing Proportionality in the Proportional Odds Model for Ordinal Logistic Regression. Biometrics, 46(4). Link
- Fox, J. and Weisberg, S., An R Companion to Applied Regression, 3rd ed., Sage (2019). Home of
car::poTest(). Link - Yee, T. W. (2010). The VGAM Package for Categorical Data Analysis. Journal of Statistical Software, 32(10). Link
- UVA Library StatLab, Fitting and Interpreting a Proportional Odds Model. Link
- Agresti, A. (2010). Analysis of Ordinal Categorical Data, 2nd ed., Wiley. Link
Continue Learning
- Logistic Regression in R: From glm() to Odds Ratios, ROC, and AUC: the binary-outcome foundation that ordinal regression extends.
- Multinomial Logistic Regression in R: the right choice when categories have no natural order.
- Poisson Regression in R: the count-data member of the generalized linear model family.